

Stencil
Member
We often speak of black hat SEO tactics and content scraping sites are just one example of such tactics. Scraping is the act of copying all content from a website using automated scripts, usually with the intention of stealing content or completely cloning the victim’s site. Lately we have been seeing quite a high number of clients affected by these so-called scraper sites. We’ll take a look at this kind of attack in an advanced form that results in the cloned site showing up in search results in place of the original site. These plagiarized sites abuse the way Google ranks content by sending fake organic traffic and by modifying internal backlinks on the cloned website so they no longer point to the victim’s website.
How Search Results Rank Website Content
Search engines want to return the best and most relevant pages in their search results to ensure that users have the best experience and find what they are looking for. As such, pages with the same or similar content on more than one page, or more than one site are not likely to rank high in the search results. One of the factors they take into consideration is the site’s organic traffic performance. This helps determine where that site should be ranked. In addition to many other factors, Google uses redirects to track which results the searcher clicks on within the search engine results page (SERP), and whether the searcher returns to click other results because they did not find what they were looking for.
As per study by Chitika in 2013:
Sites listed on the first Google search results page generate 92% of all traffic from an average search.
It makes sense that any kind of SEO targeting attack aims to get the best results they can within Google Search results can so that their activity can be successful and generate as much revenue as possible, or simply damage the SEO of the targeted website.
Signs of Being Affected by Scraper Sites
Content scraping tactics allow attackers to abuse the relationship your website has with search engines by copying your content and making it so that they are unable to determine which is the authoritative source. The worst part of this kind of attack is that you only notice it when it’s already too late – either when your search engine results page (SERP) rankings drop or you see other websites on the results page that are not yours.
I created scenario to demonstrate this attack for better understanding. Let’s assume that the victim’s website is hack.me and attacker.me is the cloned website.
Before and after the attack:
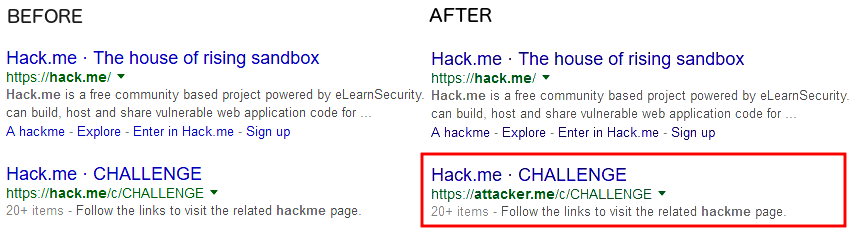
In this image we see that the attacker has effectively stolen the original website’s ranking within Google search.
An important step in knowing how to better handle this is to identify how exactly the content is being stolen:
How Websites Get Scraped
To demonstrate an example of how this attack happens, we can look at a script one of our developers put together (Lee Howarth):
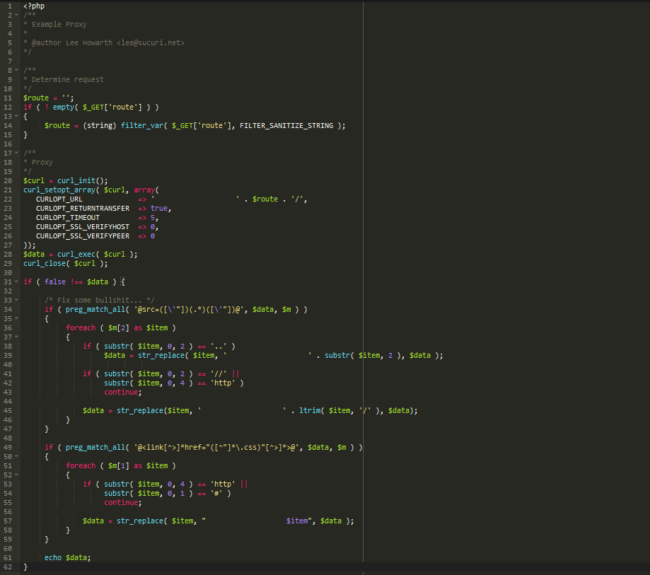
This is all that it takes, in terms of code, to grab all the content from a website and still keep it functioning. It can be made even simpler than that because, to Googlebot, the site doesn’t need to look neat. All it needs is to have the same contents and assets.
Now that the code is ready, the next step is to generate as many hits as possible on the cloned website within Google. What this will do is increase the priority of that website in Google’s eyes. Once the number of hits gets high enough (among other various factors) the copied website’s search results will start to replace the victim’s site. To get the required hits, attackers make partial use of the rank that the attacker’s site already has then they get a bit more by posting the copied pages across their network of attack websites or even by making use of click farms (companies with low-paid workers used for fraudulent activities to generate clicks for SEO or revenue increase).
Once they succeed in stealing your results, they can make sudden changes to the site for any kind of malicious / malware-serving purpose or even just to feed their ongoing spam campaigns
Has My Site Been Compromised?
No.
This part is sometimes hard to understand because your site is being affected but not compromised. There is no need for a compromise for this kind of attack to work. The website that is stealing your results is the one that is compromised.
How to Fight Back
Let’s take a look at a few ways that we have to prevent and/or fix this.
If your content data is already stored on the website then you should really try all the options to get the issue resolved as soon as possible.
Prevent Your Website SEO From Being Stolen
There is no 100% guaranteed way to stop content scrapers. Like most hackers and black hats, they will always find a way to get around any protection you put in place. There are many services like Grammarly and Copyscape which you can use to find copied content from your site. Or you can simply pick up a line from one of your posts and do a Google search with quotes (“line to look for”) and it should find all copied content if it was already indexed by Google.
The thought of being the target of an SEO attack shouldn’t leave you feeling vulnerable. It should encourage you to do regular checks and improve your security posture. There are a number of ways to eliminate a page from the SERPs, as detailed above.
If you do operate in a competitive sector it’s best to be proactive. Regular content reviews and duplicate checks either internal or external should be a part of your SEO strategy.
Source :
Cloned Website Stealing Google Rankings
How Search Results Rank Website Content
Search engines want to return the best and most relevant pages in their search results to ensure that users have the best experience and find what they are looking for. As such, pages with the same or similar content on more than one page, or more than one site are not likely to rank high in the search results. One of the factors they take into consideration is the site’s organic traffic performance. This helps determine where that site should be ranked. In addition to many other factors, Google uses redirects to track which results the searcher clicks on within the search engine results page (SERP), and whether the searcher returns to click other results because they did not find what they were looking for.
As per study by Chitika in 2013:
Sites listed on the first Google search results page generate 92% of all traffic from an average search.
It makes sense that any kind of SEO targeting attack aims to get the best results they can within Google Search results can so that their activity can be successful and generate as much revenue as possible, or simply damage the SEO of the targeted website.
Signs of Being Affected by Scraper Sites
Content scraping tactics allow attackers to abuse the relationship your website has with search engines by copying your content and making it so that they are unable to determine which is the authoritative source. The worst part of this kind of attack is that you only notice it when it’s already too late – either when your search engine results page (SERP) rankings drop or you see other websites on the results page that are not yours.
I created scenario to demonstrate this attack for better understanding. Let’s assume that the victim’s website is hack.me and attacker.me is the cloned website.
Before and after the attack:
In this image we see that the attacker has effectively stolen the original website’s ranking within Google search.
An important step in knowing how to better handle this is to identify how exactly the content is being stolen:
- If changing content on your website immediately changes the content on the cloned website this means that it’s an automated script running.
- If changing the content on your website makes no difference on the other website then it means that the data is already stored.
How Websites Get Scraped
To demonstrate an example of how this attack happens, we can look at a script one of our developers put together (Lee Howarth):
This is all that it takes, in terms of code, to grab all the content from a website and still keep it functioning. It can be made even simpler than that because, to Googlebot, the site doesn’t need to look neat. All it needs is to have the same contents and assets.
Now that the code is ready, the next step is to generate as many hits as possible on the cloned website within Google. What this will do is increase the priority of that website in Google’s eyes. Once the number of hits gets high enough (among other various factors) the copied website’s search results will start to replace the victim’s site. To get the required hits, attackers make partial use of the rank that the attacker’s site already has then they get a bit more by posting the copied pages across their network of attack websites or even by making use of click farms (companies with low-paid workers used for fraudulent activities to generate clicks for SEO or revenue increase).
Once they succeed in stealing your results, they can make sudden changes to the site for any kind of malicious / malware-serving purpose or even just to feed their ongoing spam campaigns
Has My Site Been Compromised?
No.
This part is sometimes hard to understand because your site is being affected but not compromised. There is no need for a compromise for this kind of attack to work. The website that is stealing your results is the one that is compromised.
How to Fight Back
Let’s take a look at a few ways that we have to prevent and/or fix this.
- Make use of the rel=canonical tag within each page. This is a tag that tells the Search Index crawler bots which domain that the content actually belongs to. To better explain this, read this detailed article on rel=canonical by Yoast. This is something that most SEO plugins and practitioners should already add by default.
- Contact the owner of the compromised website. As I referenced above, someone else’s website is being used to attack your website, as such it’s a good idea to get in touch with them either through WHOIS information, or by social media like Twitter. Most websites nowadays include social media information directly on their homepage so it should be fairly easy to contact someone to inform them that they have been compromised and request they get the environment secured. (And it always feels good to be a good Samaritan no?)
- Find the WHOIS information for the cloned site. You can look up WHOIS information for the cloned site or make use of WHOIS services to find out who is hosting the cloned website. Get in touch with their abuse department or live support if available, and inform them of the event and request that it be stopped. If the site is using a CDN or a Web Application Firewall (WAF) then don’t hesitate to contact those vendors as well, so that they can forward the request on to the hosting provider or take direct action themselves.
- Set-up a Google alert. You can get Google to alert you if any sites publish an exact match to a title of your posts. It should alert you the moment your content is being stolen which is great, as its free and allows you to stop the issue before it becomes problematic.
- Block requests from the cloned site. By identifying the IP of the cloned site, you can request that your hosting provider block all requests from that IP. An easy way of achieving this is by adding a few lines to your .htaccess. Let’s say that the cloned site has the IP 192.168.190.190, you could add this to your .htaccess:
order allow,deny
deny from 192.168.190.190
allow from all - Report copied content to Google. Once you have identified your copied content, go to Google DMCA page or visit this direct link to the global form, and select Web Search. Be sure to fill everything out appropriately so you have all the nefarious links removed and your traffic returned within a couple of days
If your content data is already stored on the website then you should really try all the options to get the issue resolved as soon as possible.
Prevent Your Website SEO From Being Stolen
There is no 100% guaranteed way to stop content scrapers. Like most hackers and black hats, they will always find a way to get around any protection you put in place. There are many services like Grammarly and Copyscape which you can use to find copied content from your site. Or you can simply pick up a line from one of your posts and do a Google search with quotes (“line to look for”) and it should find all copied content if it was already indexed by Google.
The thought of being the target of an SEO attack shouldn’t leave you feeling vulnerable. It should encourage you to do regular checks and improve your security posture. There are a number of ways to eliminate a page from the SERPs, as detailed above.
If you do operate in a competitive sector it’s best to be proactive. Regular content reviews and duplicate checks either internal or external should be a part of your SEO strategy.
Source :
Cloned Website Stealing Google Rankings

")